
CKA #2 Core Concepts, #3 Scheduling
Certified Kubernetes Administrator (CKA) with Practice Tests 강의를 듣고 몰랐던 내용, 알고 있어도 중요하다고 생각하는 내용 등을 추가적인 공부와 함께 간략히 정리한 글입니다.
Index
- CKA #2 Core Concepts, #3 Scheduling
- CKA #4 Logging & Monitoring, #5 Application LifeCycle Management
- CKA #6 Cluster Maintenance
- CKA #7 Security
- CKA #8 Storage
- CKA #9 Networking
Introduction
섹션2는 기본적인 내용들이라 대체로 쉬웠다. 대부분 기본적인 골자를 설명하는 것이기도 하고, 기본적인 리소스를 생성하는 방법에 대해 다룬다. 알고 있던 기본적인 내용은 생략하고, 들으면서 내가 써볼 일이 없어서 몰랐던 부분들 혹은 알고 있었지만 꽤 중요하거나, CKA 시험을 위해서라도 외워두면 좋을 팁들 위주로 기록했다.
특히 파일을 만들어서 delcarative하게 관리하는 작업은 많이 해보았지만 imperative하게 동작해본 적은 거의 없어서… 특히 kubectl run이나 kubectl create 같은 명령어를 잘 안쓰다보니 익숙하지가 않아 기록해두기로 했다.
apiVersion - v1 vs apps/v1
v1 - 쿠버네티스에서 발행한 첫 stable release API (대부분의 기본적인 API)
apps/v1 - 쿠버네티스 Common API들. Deployment, RollingUpdate, ReplicaSet 등
리소스 별로 다양한 apiVersion이 있다. (rbac.authorization.k8s.io/v1, networking.k8s.io/v1 등)
그래서 이것을 확인하려면, kubectl explain [리소스명] 명령어를 쳐보는 것이 마음이 편하다.
ReplicaSet vs ReplicationController
대충 yaml 파일 쓰는 법이 다르다는 것은 안다. 그런데 본질적으로 뭐가 다른걸까? ReplicationController는 쿠버네티스 프로젝트 초기부터 존재했다. 근데 나는 현업에서 ReplcationController를 쓴 기억이 없다. 나는 ReplicaSet만 썼다. 실제로도 Deployment와 ReplicaSet을 사용하는게 추세라고 한다.
셀렉터
- 레플리카셋은 파드의 레이블 셀렉터를 사용해 복제 대상을 선택. 특정 레이블을 가진 파드들만 복제할 수 있음. → 레플리카셋은 레플리카셋으로 만들어지지 않은 파드도 셀렉터를 이용해 동작에 고려할 수 있다.
- 레플리카 컨트롤러는 레이블 셀렉터로 파드 선택을 할 수 없음
롤링 업데이트 유무
- 레플리카셋은 롤링 업데이트를 지원하고, 어플리케이션의 버전을 업데이트할 때 일정한 수의 파드를 유지하면서 점진적으로 업데이트가 가능함.
- 레플리카 컨트롤러는 롤링 업데이트를 직접적으로 지원하지 않음. 업데이트를 수동으로 진행해야 함.
레플리카셋은 yaml에 selector를 정의하고, template도 정의해두어야 한다. 왜? 만약 이미 desired state에 해당하는 개수가 배포되어 있다고 하더라도, 이 파드가 죽을 경우, 레플리카셋이 template을 참고해 새 파드를 생성해 desired state를 충족시켜야 하기 때문이다.
TIP: 파일 없이 replicaset의 replicas 조정하기
현업에서는 yaml 파일들로 관리하거나 오토스케일을 걸어버리니 쓸 일이 없었는데…
kubectl scale --replicas=6 replicaset myapp-replicaset
TIP: 파일없이 리소스 수정하기
얘도 현업에서는 yaml 파일들로 관리하다보니 잘안쓰는 기능이였는데, CKA 시험에서 yaml 파일을 모두 작성하면 시간이 너무 오래 걸리니 edit 유용한 기능일 듯
kubectl edit 리소스명 리소스이름
Deployment와 ReplicaSet의 차이점
Deployment: 파드와 레플리카셋(ReplicaSet)에 대한 선언적 업데이트를 제공
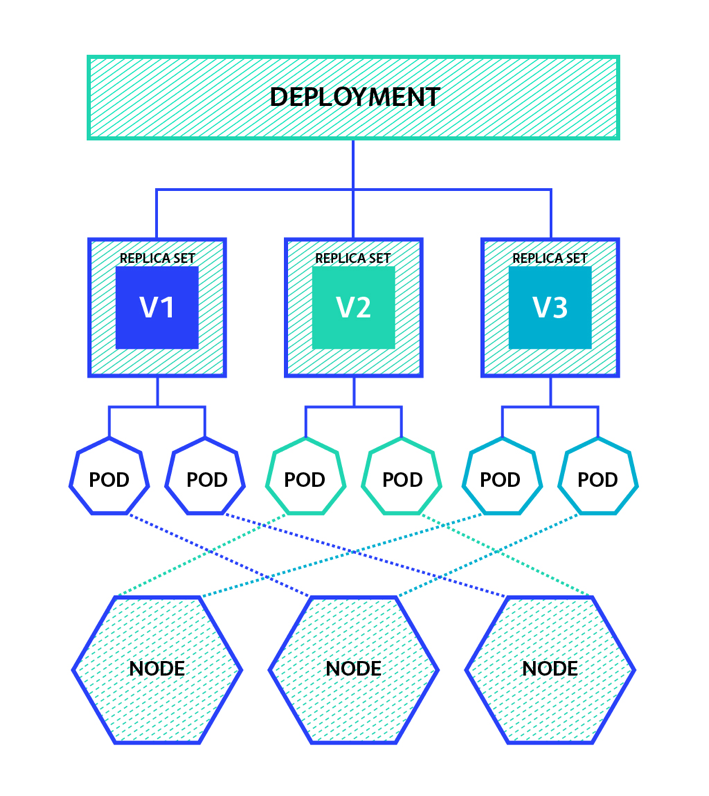 이미지 출처: ReplicaSet과 Deployment
이미지 출처: ReplicaSet과 Deployment
- Rolling Update : 새 버전 파드를 하나 생성하고, 이전 버전 파드를 하나 삭제하는 방식을 반복하며 동작
- Recreate : 기존 버전 파드 삭제 후 재생성 (파드가 존재하지 않는 순간이 생김)
- Blue/Green : 기존 버전 파드를 유지한 후 새 버전 파드를 생성하고, Service가 한 번에 트래픽 전달 대상을 교체함. 이전 버전과 새 버전이 공존하지 않지만, 순간적으로 파드가 2배가 되는 단점 존재
- Canary : 구버전 신버전 파드를 모두 만들고, 트래픽 양을 조절한 뒤 교체함
수동 스케줄링
POD가 떠있는 상태로 노드에서 다른 노드로 옮길 수 없다. → 파드도 결국 컨테이너고, 컨테이너는 프로세스다. 노드들은 서로 다른 컴퓨터다. 아무런 변동 없이 한 컴퓨터의 프로세스를 다른 컴퓨터의 프로세스로 옮기는 것은 불가능하기 때문이다.
yaml 파일에서 nodeName이라는 키를 이용해서 노드를 지정해줄 수 있음
셀렉터
이건 잘 안쓰던 옵션이긴한데, 알아두면 편하게 쓸 것 같아서 기록
kubectl get pods --selector "app=App1"
Node Label 보기
--show-labels=true
Tolerations & Taints
- 파드를 노드에 스케줄링할 때 제약사항들
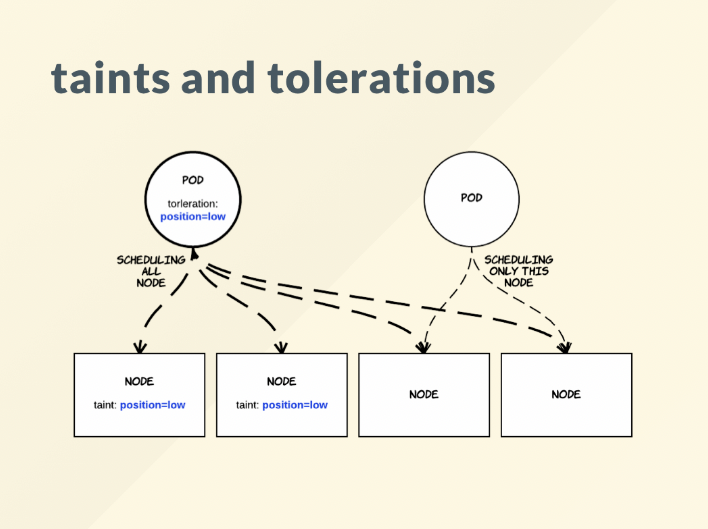 이미지 출처: Kubernetes Pod 배치전략, Taint와 Toleration에 대해 이해하고 실습해보기
이미지 출처: Kubernetes Pod 배치전략, Taint와 Toleration에 대해 이해하고 실습해보기
Taint된 노드에 Toleration된 팟은 “배치될 수 있다”이지 배치가 보장되는 것이 아니다.
Taints
kubectl describe node node01 | grep Taint
kubectl taint nodes node01 spray=mortein:NoSchedule # Key=Value:Effect
# Taint 삭제
kubectl taint nodes controlplane node-role.kubernetes.io/control-plane:NoSchedule-
- Node에 설정하는 제약
- Key=Value:Effect 형식
- Effect에는 Taint의 효과를 기술함
- NoSchedule = Taint Node에 Pod의 스케줄링을 허용하지 않음 (기존 실행 중인 파드는 그냥 두고, 이후 실행될 파드에 대해서만 스케줄링)
- NoExecute = Taint Node에 Pod의 실행을 허용하지 않음 (기존 실행 중인 파드도 방출 + 이후 실행될 파드도 스케줄링 하지 않음)
- PreferNoSchedule = Taint Node에 Pod 스케줄링을 선호하지 않음 (기존 실행 중인 파드는 그냥 두고, 앞으로 생성될 파드의 스케줄링은 비선호함. 즉 스케줄 우선순위를 최하로 낮추는 방향)
Tolerations
- Pod에 설정
- A라는 Taint를 용인할 수 있는 Toleration 설정을 가진 Pod는 A라는 Taint가 설정된 Node에 할당할 수 있다.
- tolerations는 Key, Value, Operator, Effect로 구성된다.
- Key: Taint의 Key
- Value: Taint의 Value
- Effect: Taint의 Effect
- Operator
- Exists = 허용한다는 의미인데, 조건을 만족하는 모든 노드에 배치를 허용
- operator만 조건으로 들어오면, 어떤 taint건 무시하고 스케줄링될 수 있음
- key + operator가 조건이라면, 해당 key를 가지는 모든 taint에 스케줄링될 수 있음
- Equal: key, value, effect가 모두 일치하는 Taint에 배치될 수 있음
- Exists = 허용한다는 의미인데, 조건을 만족하는 모든 노드에 배치를 허용
NodeSelectors
kubectl label nodes <node-name> <label-key>=<label-value>
kubectl label nodes <node-name> size=Large
# Pod Yaml
...
nodeSelector:
size: Large
노드 셀렉터를 이용해 파드가 배치될 노드를 선택할 수 있게끔 만들수 있다.
하지만 명시적으로 배치될 노드를 선택하는 경우는 가능하지만, 조건이나 범위 등이 주어지는 상황에서 처리할 수 없다는 문제가 있다. 그래서 Affinity가 생겼다.
# Pod Yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoreDuringExecution:
nodeSelctorTerms:
- matchExpressions:
- key: size
operator: In
values:
- Large
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 10
preference:
- matchExpressions:
- key: disktype
operator: In
values:
- hdd
참고자료 - [k8s] 파드 스케쥴링 - Node Affinity(노드 어피니티)
- requiredDuringSchedulingIgnoreDuringExecution = 스케쥴링하는 동안 꼭 필요한 조건
- operator
- In : values[] 필드에 설정한 값 중 노드 레이블에 있는 값과 하나라도 일치하는지 확인
- NotIn: values[] 필드에 설정한 값과 노드 레이블에 있는 값이 모두 불일치하는지 확인
- Exists: key 필드에 설정한 값이 노드 레이블에 있는지만 확인 (values[] 없어도 됨)
- DoesNotExist: key 필드에 설정한 값이 노드 레이블에 없는지만 확인
- Gt: GreaterThan → values[] 필드에 설정한 값이 노드 레이블보다 더 큰 숫자형 데이터인지 확인 (이 때 values[] 필드에는 값이 하나만 있어야 함)
- Lt: Lower Then → values[] 필드에 설정한 값이 노드 레이블보다 더 작은 숫자형 데이터인지 확인 (이 때 values[] 필드에는 값이 하나만 있어야 함)
- operator
- preferredDuringSchedulingIgnoreDuringExecution = 스케줄링하는 동안 만족하면 좋은 조건
- weight 필드를 사용한다는 점 (값은 1~100)
- nodeSelectorTerms[] 필드 대신 preference 필드를 사용한다는 점이 차이점
- 해당 조건에 일치하는 것을 선호한다는 의미
- 여러 개의 matchExpressions[] 필드 안의 설정들이 노드의 설정과 일치할 때, weight 필드값을 더하고, 모든 노드 중에서 weight 필드 값의 합계가 가장 큰 노드를 선택함
- 두 필드는 모두 실행 중에 조건이 바뀌어도 무시한다. 파드가 이미 스케줄링되어 특정 노드에서 실행 중이라면, 중간에 해당 조건이 변경되더라도 이미 실행 중인 파드는 변화없이 계속 실행된다는 의미
- requiredDuringSchedulingRequiredDuringExecution
Taint/Toleration과 NodeAffinity 함께 사용하기
Taint/Toleration 만으로는 특정 팟이 특정 노드에 꽂힌다는 보장을 할 수 없다.
Taint된 노드에 Toleration된 팟은 “배치될 수 있다”이지 배치가 보장되는 것이 아니기 때문. 따라서, NodeAffinity까지 적절히 사용하여 특정 파드를 특정 노드에 배치시켜야 한다.
컨테이너는 pod memory limit을 걸어도 메모리를 더 쓸 수 있다.
하지만 memory limit보다 더 많은 메모리를 계속해서 쓰면, 파드가 터미네이트 당한다. OOM으로 종료된다.
리소스 사용량 제한 → 네임스페이스 단위로 쿼터를 제공할 수 있다.
- LimitRange → 파드 단위로 자원을 제한하는 리소스
- ResourceQuota → 네임스페이스 단위로 자원을 제한하는 리소스
Static Pod 개념
- kube-apiserver에 의존하지 않고, kubelet이 직접 파드를 생성, 관리하는 것이 특징
- 레플리카셋 등을 생성할 수 없음. 파드로만 가능.
- 클러스터의 컴포넌트(kube-api, etcd 등)를 정적 파드로 생성해 장애를 방지하고 설치를 용이하게 하는 등의 목적으로 활용 가능
- 정작 파드 경로에 yaml 파일이 존재할 경우 자동으로 파드를 생성하고, 재생성되고, 파일을 수정하면 자동으로 새로운 파드가 뜬다. 하지만 파드의 삭제는 yaml을 삭제하고 파드도 수동으로 삭제해주어야 한다.
- manifest는 그냥 Pod.yaml이다. yaml 파일을 /etc/kubernetes/manifests에 저장하면 바로 static pod가 생성된다.
- 그런데 만약 이 경로가 아니라면, 각 노드의 /var/lib/kubelet/config.yaml에 staticPodPath 정보가 있을 것이다.
Multiple Scheduler
- kube-scheduler를 쓰지 않고 개별 스케줄러를 생성해 리소스를 배포하는 경우 사용할 수 있음
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
schedulerName: my-custom-controller
- 스케줄러가 올바르게 배정되지 않으면 파드가 계속 pending 상태로 남게된다.
스케줄러가 잘 동작하는지 보고 싶다면, 아래 명령어를 통해 확인할 수 있다.
kubectl get events -o wide
kubectl logs my-custom-scheduler --namespace=kube-system
Custom Scheduler yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: my-scheduler
name: my-scheduler
namespace: kube-system
spec:
serviceAccountName: my-scheduler
containers:
- command:
- /usr/local/bin/kube-scheduler
- --config=/etc/kubernetes/my-scheduler/my-scheduler-config.yaml
image: <use-correct-image>
livenessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
initialDelaySeconds: 15
name: kube-second-scheduler
readinessProbe:
httpGet:
path: /healthz
port: 10259
scheme: HTTPS
resources:
requests:
cpu: '0.1'
securityContext:
privileged: false
volumeMounts:
- name: config-volume
mountPath: /etc/kubernetes/my-scheduler
hostNetwork: false
hostPID: false
volumes:
- name: config-volume
configMap:
name: my-scheduler-config
POD Scheduling
- 파드의 우선순위를 설정할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
priorityClassName: high-priority
containers:
- image: nginx
name: nginx
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000 # Priority Value
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
- SchedulingQueue: 파드는 생성하면 스케줄링 큐에 들어가게 된다. 스케줄링 큐 단계에서 우선순위에 따른 정렬이 일어난다.
- Filtering: 이후 파드는 스케줄링 큐에서 필터 단계로 옮겨가는데, 필터 단계에서 파드를 실행할 수 없는 노드(리소스가 부족한 경우 등)가 걸러진다.
- Scoring: 이후 파드는 스코어링 단계로 넘어간다. weight 등의 기준을 통해 각 노드마다 점수를 매긴다. 해당 파드에 필요한 CPU를 배정한 이후 남는 자원의 양 등을 근거로 점수를 매기게 된다.
- Binding: 마지막으로 바인딩 단계에서 앞서 점수 매기기를 통해 선정된 노드에 파드가 바인딩된다.
각 단계는 플러그인으로 이루어져 있다. 자신만의 플러그인을 작성해서 붙일 수도 있다. Extension을 지원한다.
- SchedulingQueue
- PrioritySort: 파드 우선순위 정보를 바탕으로 정렬 기능을 제공하는 플러그인
- Filtering
- NodeResourceFit: 포드에서 요구하는 자원이 충분한 노드를 식별하고 부족한 노드들을 필터링하는 플러그인
- NodeName: 파드 yaml에서 작성한 nodeName이 있는지 확인하고 일치하지 않는 노드를 필터링하는 플러그인
- NodeUnschedulable: 언스케줄 플래그가 true인 노드들을 필터링하는 플러그인
- Scoring
- NodeResourceFit: 각 노드의 리소스를 바탕으로 자원을 계산해 점수를 매긴다. 앞의 필터링 단계의 NodeResourceFit 플러그인과 같은 플러그인이다.
- ImageLocality: 각 노드에서 사용되는 컨테이너 이미지를 가진 이미지에 높은 점수를 주는 플러그인
- Binding
- DefaultBinder
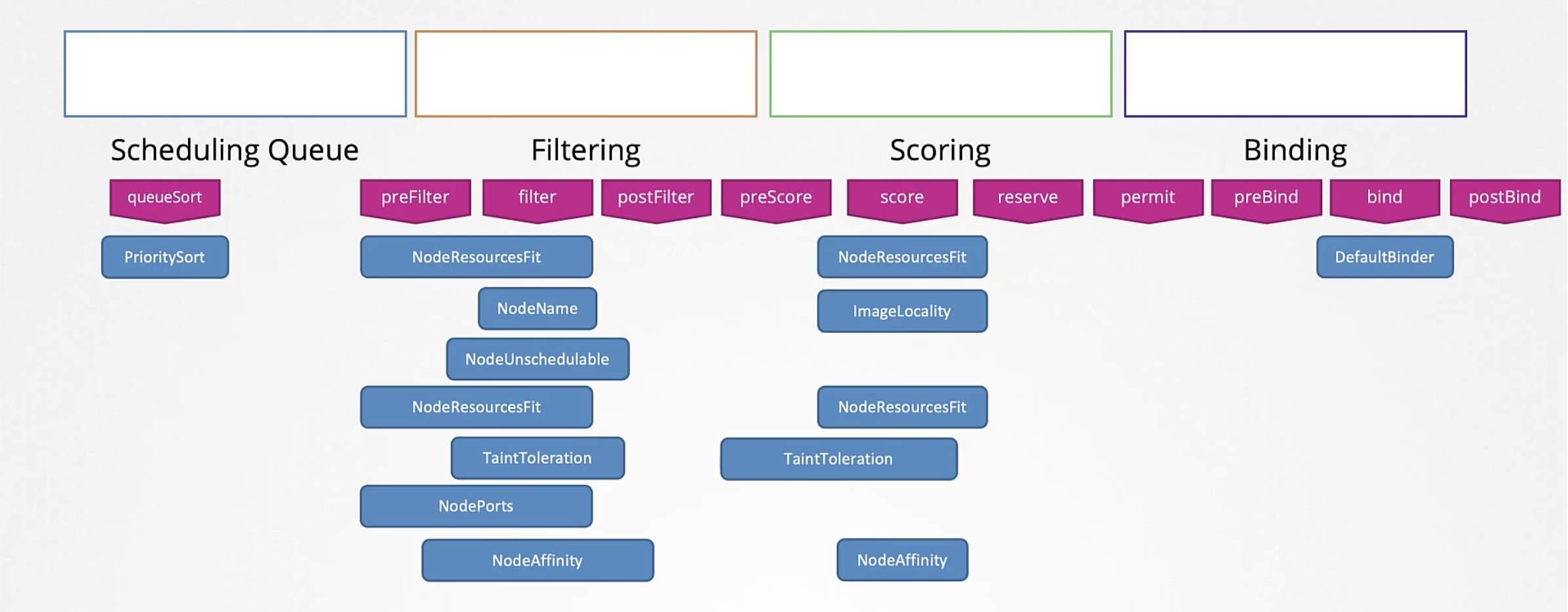 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: my-scheduler-2
plugins:
score:
disabled:
- name: TaintToleration
enabled:
- name: MyCustomPluginA
- name: MyCustomPluginB
여러 스케줄러를 쓸 때는 RaceCondition이 발생하는 것에 주의해야한다. 서로 다른 두 개 이상의 스케줄러가 동시에 스케줄링을 하게 될 때 동시에 같은 노드에 파드를 스케줄링할 때 문제가 발생할 수 있음에 유의하자.