
CKA #9 Networking
영어로 네트워크를 설명해서 그런지 어려운 부분이 있었습니다. 특히 CNI에 관한 배경지식이 부족해서인지 아직 100% 이해하지 못했습니다. 그래서 차후 추가로 공부를 하면서 글을 다듬어볼 생각입니다.
Index
- CKA #2 Core Concepts, #3 Scheduling
- CKA #4 Logging & Monitoring, #5 Application LifeCycle Management
- CKA #6 Cluster Maintenance
- CKA #7 Security
- CKA #8 Storage
- CKA #9 Networking
Prerequisite - Switching Routing
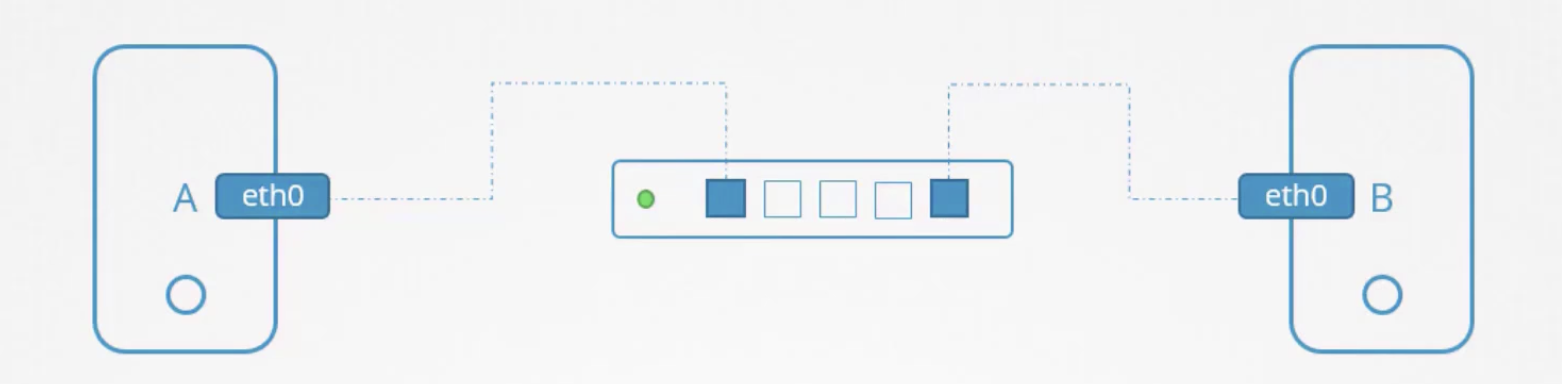
- A와 B를 스위치에 연결하려면, 각 호스트에는 인터페이스가 필요하다.
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
ip link
# 호스트 A에서
ip addr add 192.168.1.10/24 dev eth0
# 호스트 B에서
ip addr add 192.168.1.11/24 dev eth0
ip addr [ COMMAND ] ADDRESS dev IFNAME
# Device eth0에 192.168.1.10 NetMask 24를 추가
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
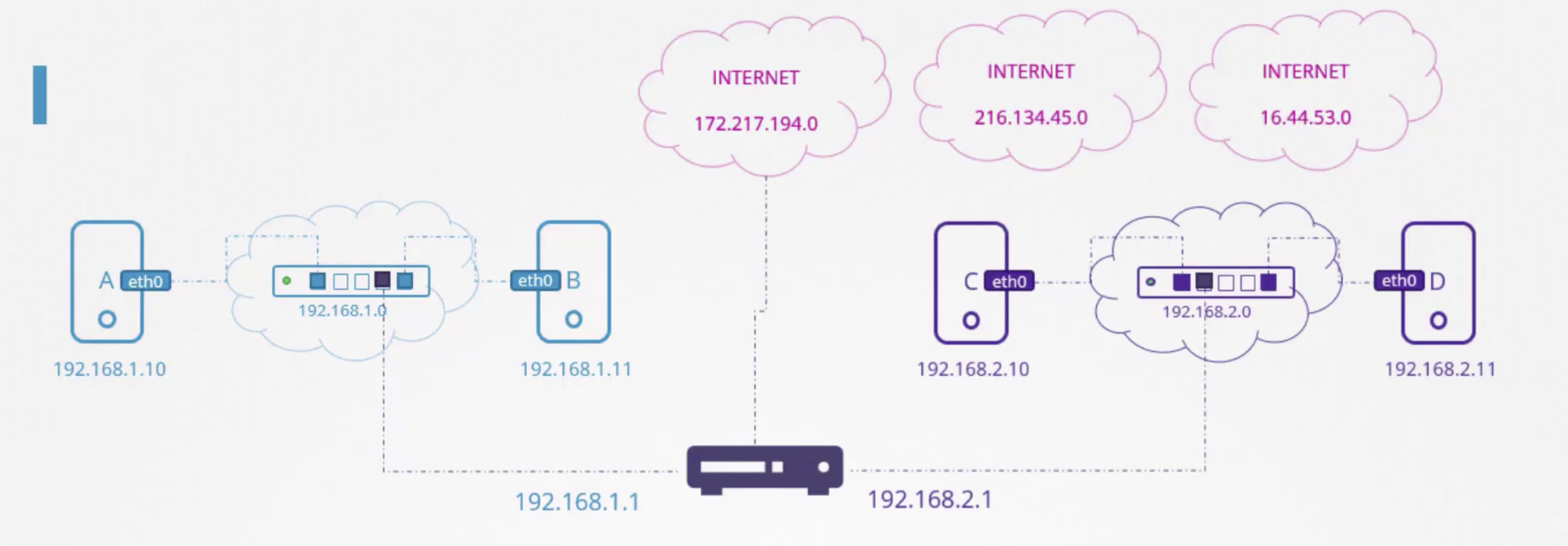
route # 라우팅 테이블을 보여주는 명령어
ip route add 192.168.1.0/24 via 192.168.2.1
# 192.168.1.0/24 범위의 목적지로 향하는 패킷은 192.168.2.1 로 보낸다. (C의 입장)
ip route add 172.217.194.0/24 via 192.168.2.1
ip route add default via 192.168.2.1 # 디폴트 게이트웨이 설정
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
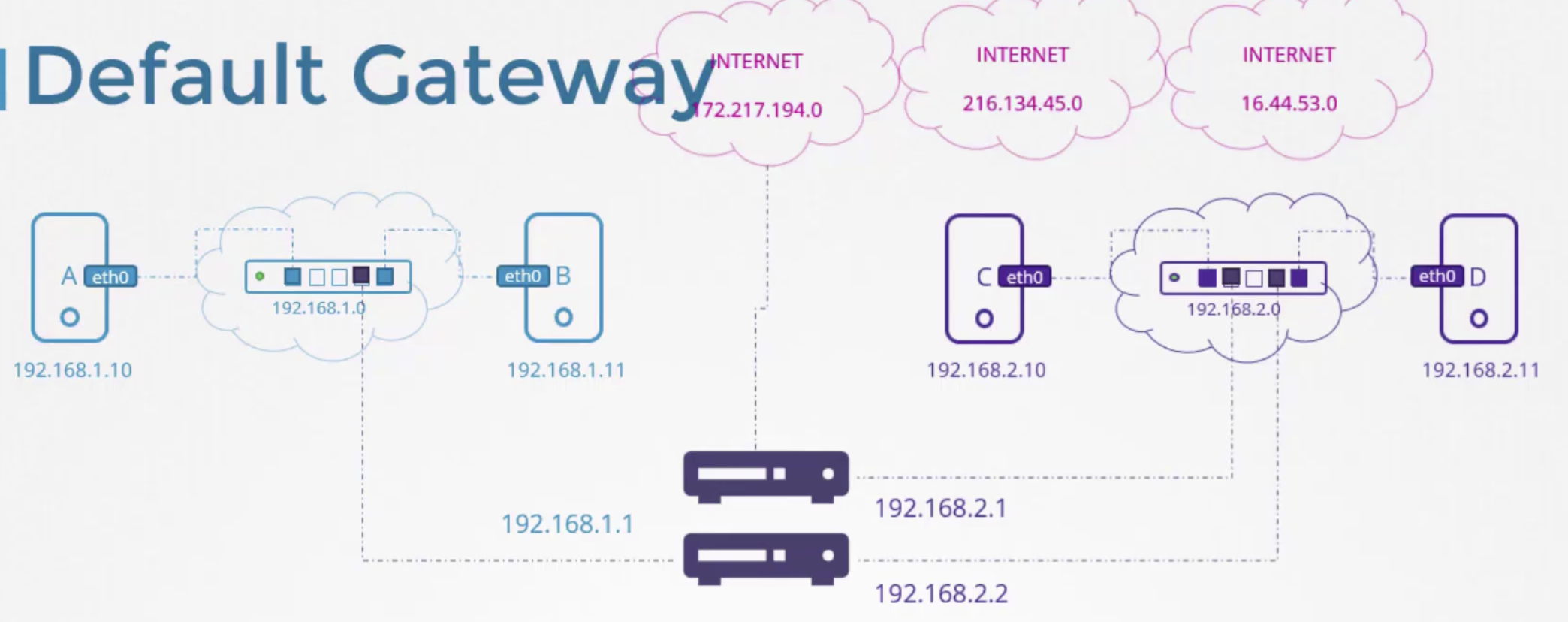
# 사설망과 밖으로 나가는 망을 분리하고 싶다면,
ip route add 192.168.1.0/24 via 192.168.2.2
ip route add default via 192.168.2.1
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
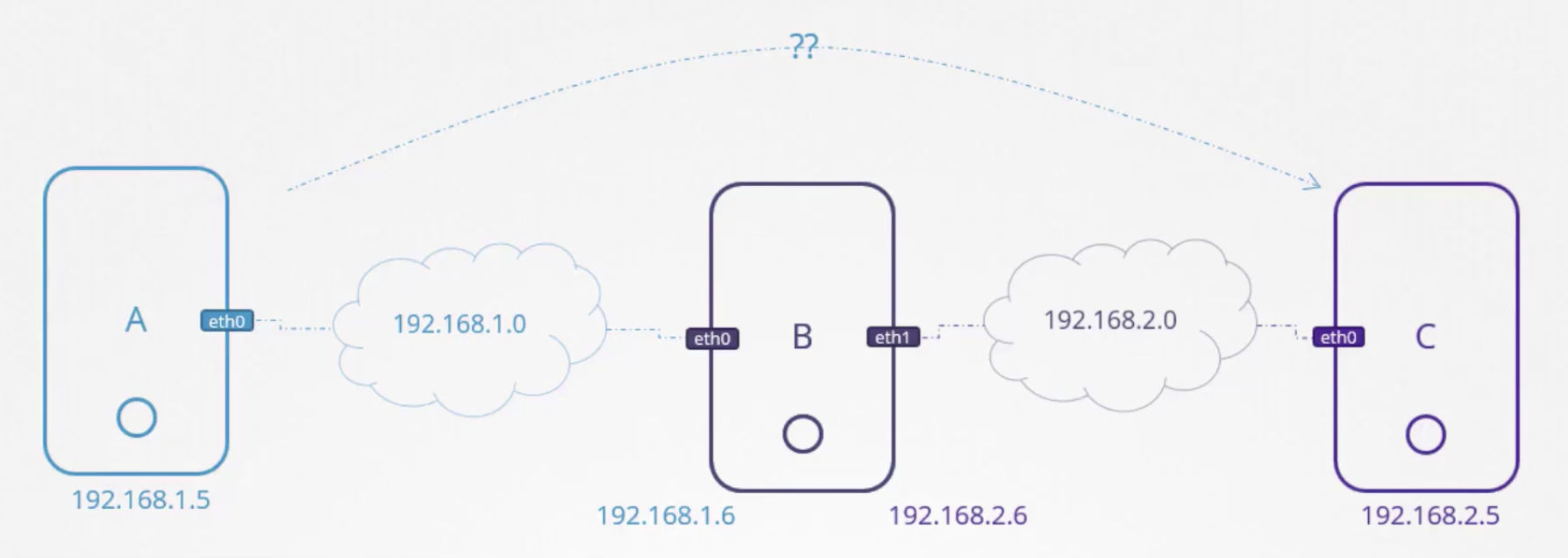
위의 상황에서, A는 C로 가지 못한다.
# A의 터미널
ping 192.168.2.5
# Connect: Network is unreachable
A에게 B를 거치면 C로 갈 수 있다고 알려주어야 한다.
# A의 터미널
ip route add 192.168.2.0/24 via 192.168.1.6
# 192.168.2.0/24로 가고 싶으면 192.168.1.6(B)에게 가라.
반대로 C도 A에게 도달하기 위해 라우트테이블을 추가해주어야 한다.
# C의 터미널
ip route add 192.168.1.0/24 via 192.168.2.6
이제 A는 C에게 핑을 날려본다.
# A의 터미널
ping 192.168.2.5
하지만 아직 아무런 응답이 없다. 왜일까. 리눅스 패킷은 한 인터페이스에서 다음 인터페이스로 전달되지 않는다.
B에서 eth0으로 받은 패킷이 eth1을 통해 다른 곳으로 전달되지 않는다. 보안 이유 때문에서다. 개인 네트워크에 eth0을 연결하고, 공용 네트워크에 eth1을 연결했다고 가정하자. 명시적으로 허용하지 않는한, 개인 네트워크에서 공용 네트워크로 메시지를 보내서는 안된다.
하지만 일단 위 예시에서는 둘 다 개인 네트워크이고, 둘 사이의 통신을 가능하도록 하기 위한 목적이기 때문에 B에 명시적으로 허용해줌으로써 다른 네트워크로 패킷을 보내도록 할 수 있다.
호스트가 인터페이스 간 패킷을 전달할 수 있는지는 /proc/sys/net/ipv4/ip_forward 에 따라 통제된다. 이 파일의 기본값은 0이다. 불가능하다는 뜻이다. 이 파일의 내용을 1로 바꾸면 핑 명령어가 정상적으로 동작하는 것을 볼 수 있다. 하지만 재부팅되면 다시 0으로 수정되는데, 이를 막고 싶다면 /etc/sysctl.conf 파일의 net.ip4.ip_forward를 1로 설정해주면 된다.
# A의 터미널
ping 192.168.2.5 # 정상적으로 Reply를 받을 수 있음
명령어 정리
ip link # 호스트에서 네트워크 인터페이스를 표시하고 수정할 수 있음
ip addr # 해당 인터페이스에 할당된 IP 주소를 볼 수 있음.
ip addr add 192.168.1.0/24 dev eth0 # 인터페이스에 IP 주소를 설정하는데 사용됨
# 그러나 이 명령어는 재부팅되면 초기화되므로 유지시키고 싶다면 /etc/network/interfaces 파일을 수정해야 한다.
route # 라우팅 테이블을 보는데 사용됨
ip route # 라우팅 테이블을 보는데 사용됨
ip route add 192.168.1.0/24 via 192.168.2.1 # 라우팅 테이블에 항목을 추가하는데 사용됨
cat /proc/sys/net/ipv4/ip_forward # 패킷 포워딩이 가능한지 확인할 수 있는 명령어
Prerequisite - DNS
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
B에 db라는 이름을 붙이고 싶다. A에서 db라는 이름으로 핑을 날려보지만, 당연히 날려지지 않는다. A에게 db라는 이/ty름이 192.168.1.11을 가리킨다고 알려주자.
# /etc/hosts 파일에 다음을 추가한다.
192.168.1.11 db
이제 호스트 A에서 ping db 명령어가 정상적으로 동작한다.
호스트 A는 시스템 B의 실제 이름이 db인지 확인하지 않는다. 시스템 B에서 호스트 이름을 확인하는 hostname 명령을 실행하면 host-2라고 나오지만, A에게는 상관없다. A는 A의 호스트 파일을 따르기 때문이다.
이렇게 호스트 이름을 IP주소로 해석하는 행동을 Name Resolution이라고 부른다.
옛날에는 소수의 시스템 안에서 /etc/hosts를 수정하는 방식으로 동작시켰다. 그런데 이제 네트워크가 커지고 너무 항목이 많아져서 hosts 파일 하나로 관리하기 힘들어지기 시작했다. 서버 중 하나의 IP가 변경되면 나머지 모든 호스트의 hosts 파일을 수정해야 했다. 그래서 이제 이런 일들을 관리할 수 있는 중앙 서버를 만들기로 했다. 이를 DNS 서버라고 부른다.
DNS 서버도 IP를 가지고 있다. 모든 호스트들은 /etc/resolve.conf DNS Configuration 파일을 가지고 있다. 여기 DNS 서버 IP를 추가한다.
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
cat /etc/resolv.conf
nameserver 192.168.1.100
이렇게 설정을 다 해주고 나면, 호스트들은 자신이 모르는 hostname을 만나면 DNS 서버를 통해 확인한다.
만약 /etc/hosts파일과 DNS 서버에 둘 다 동일한 hostname이 있다면 어떻게 될까? 이 경우에는 호스트는 먼저 로컬에 있는 hosts 파일을 보고, 없으면 DNS 서버에 요청한다. 하지만 원한다면 순서를 바꿀 수 있다. 순서에 대한 정보는 /etc/nsswitch.conf 파일 안에 정의되어 있다.
# /etc/nsswitch.conf
...
hosts: files dns
...
Prerequisite - Network Namespaces
도커 컨테이너가 네트워크 격리를 위해 사용하는 기술
컨테이너를 만들 때 호스트나 다른 컨테이너가 보이지 않도록 네임스페이스를 이용해 격리되도록 해야한다. 호스트는 컨테이너 내에서 실행되는 프로세스를 포함해 모든 프로세스들을 볼 수 있다.
ps aux
Nginx를 실행한 컨테이너 안에서 ps aux 명령어를 실행하면 nginx 프로세스는 PID 1로 보이겠지만, 호스트에서 보면 해당 프로세스는 평범한 프로세스 중 하나로 보인다. PID도 다른 값을 갖는다. 이것이 네임스페이스의 원리다.
네트워킹에 관해서 호스트는 로컬 네트워크를 연결하는 eth0 인터페이스가 있다. 호스트는 라우팅 테이블과 ARP 테이블을 가지고 있다. 다른 네트워크 정보도 가지고 있다.
컨테이너가 생성되면 컨테이너를 위한 네트워크 네임스페이스를 생성한다. 컨테이너 내에서 컨테이너는 고유의 가상 인터페이스 라우팅, ARP 테이블을 가질 수 있다.
리눅스 호스트에 새 네트워크 네임스페이스는 다음과 같이 만들 수 있다.
ip netns add red # red 네임스페이스 생성
ip netns add blue # blue 네임스페이스 생성
ip link # 입력하면 eth0 인터페이스를 볼 수 있다.
ip netns exec red ip link # red 네임스페이스 안에서 ip link 명령어를 실행
ip -n red link # 같은 명령어
네임스페이스 안에서 ip link를 입력해보아도, 루프백 인터페이스만 보인다. eth0이 보이지 않는다.
arp # ARP Table 출력 명령어
rout # Route Table 출력 명령어
마찬가지로 호스트에서는 잘 보이지만, 네임스페이스 내부에서는 아무 것도 뜨지 않는 것을 확인할 수 있다.
네트워크 네임스페이스는 아무 연결이 없다는 점을 확인할 수 있다.
ip link add veth-red type veth peer name veth-blue
# red ns와 blue ns를 네트워크 연결시켜주는 명령어
ip link set veth-red netns red
ip link set veth-blue netns blue
# 각 네임스페이스에 각 인터페이스를 연결
ip -n red addr add 192.168.15.1 dev veth-red
ip -n blue addr add 192.168.15.2 dev veth-blue
# IP를 veth 인터페이스에 할당
ip -n red link set veth-red up
ip -n blue link set veth-blue up
ip netns exec red ping 192.168.15.2
# red ns에서 blue의 ip에 Ping을 날려보자
# 정상적으로 동작한다.
ip netns exec blue ping 192.168.15.1
# blue ns에서 red의 ip에 Ping을 날려본다.
# 정상적을 ㅗ동작한다.
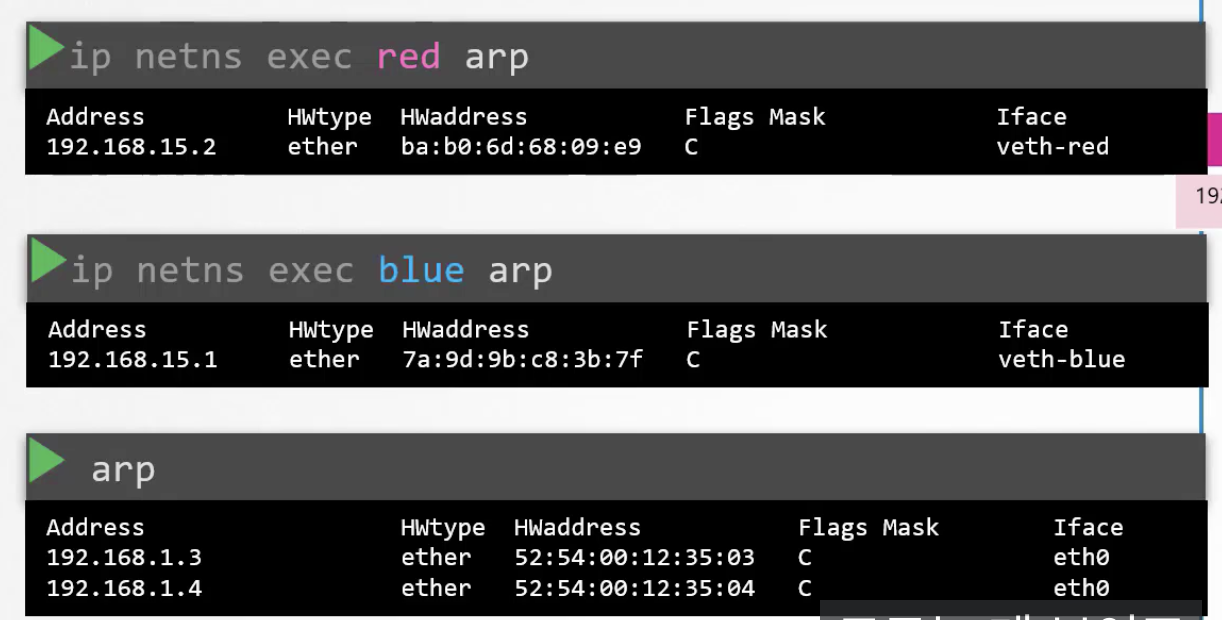
ip netns exec red arp
# red의 ARP 테이블에 blue의 정보가 추가되어 있음
ip netns exec blue arp
# blue의 ARP 테이블에 red의 정보가 추가되어 있음
ip -n red link del veth-red # red-blue 간 링크 삭제
# 하나만 삭제해도 반대편은 자동으로 삭제된다.
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
veth 간의 연결이 호스트의 ARP 테이블에서는 안보이는 모습.
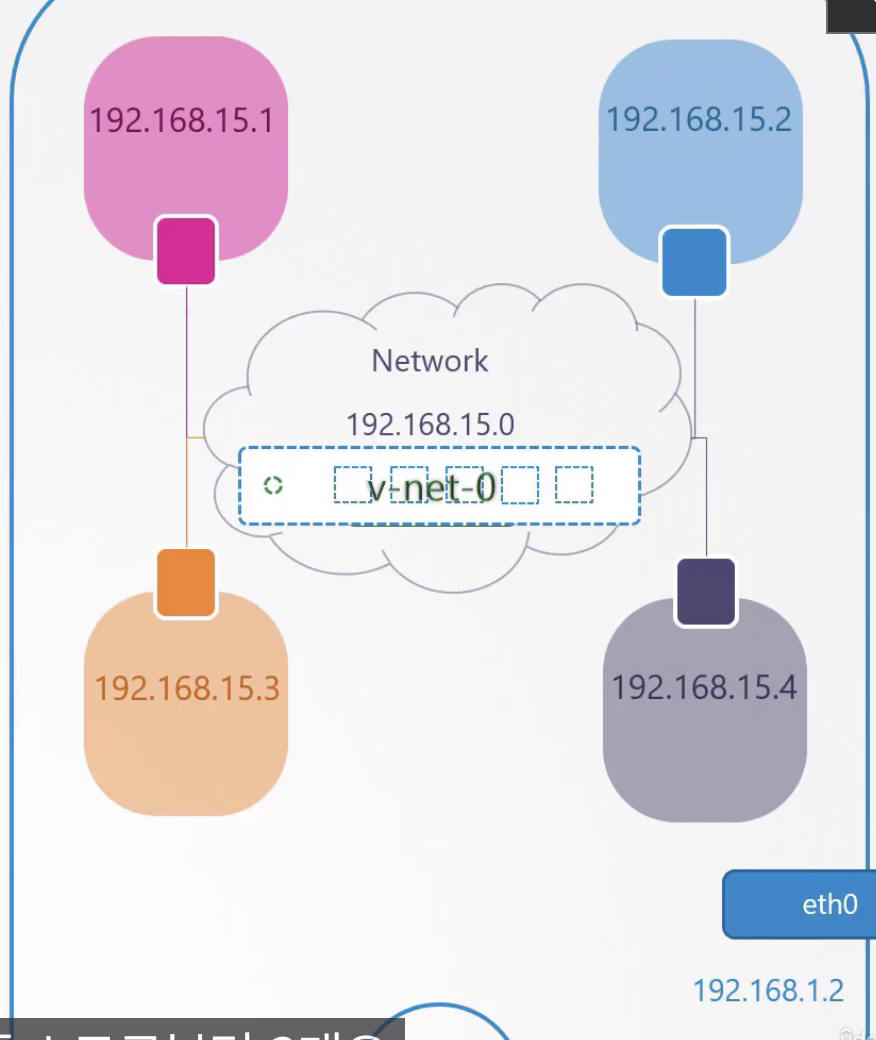
만약에 더 많은 개수의 Namespace가 존재하고 서로 연결해주려면 어떻게 해야할까? 물리 세계처럼, 호스트 내부에 가상 네트워크를 만들어야 한다. 네트워크를 만들려면 스위치가 필요한다. 가상 네트워크를 만들려면 가상 스위치가 필요하다. 호스트 내에 가상 스위치를 생성하고 네임스페이스를 연결한다. 그럼 호스트 내에서 가상 스위치는 어떻게 만들 수 있을까? 여러 방법이 있다. Linux Bridge, Open vSwitch 등. 여기서는 리눅스 브릿지를 사용한다.
ip link add v-net-0 type bridge
# 새로운 인터페이스를 만든다. 타입은 브릿지.
ip link
# 명령어를 입력하면 v-net-0이 생성된걸 확인할 수 있다.
# 다운되어 있는 상태이니, 셋업 명령을 이용해 켜야 한다.
ip link set dev v-net-0 up
호스트의 인터페이스와 네임스페이스의 스위치라고 생각하면 된다.
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
ip link add veth-red type veth peer name veth-red-br
ip link add veth-blue type veth peer name veth-blue-br
# NS와 가상 스위치를 연결해주는 일종의 케이블을 만들었음
# 이제 네임스페이스와 케이블을 연결한다.
ip link set veth-red netns red
ip link set veth-blue netns blue
# 케이블과 가상 스위치를 연결한다.
ip link set veth-red-br master v-net-0
ip link set veth-blue-br master v-net-0
# IP를 할당한다.
ip -n red addr add 192.168.15.1 dev veth-red
ip -n blue addr add 192.168.15.2 dev veth-blue
# 켠다.
ip -n red link set veth-red up
ip -n blue link set veth-blue up
호스트에서 위에서 생성한 네트워크에 접근해보자.
ping 192.168.15.1
# Not Reachable
되지 않는다. 다른 네트워크로 인식하기 때문이다. 만약 연결하고 싶다면? 가상 스위치 인터페이스는 호스트에 존재했었다. 아까 ip link 명령어를 통해 확인했다. 그렇다면 v-net-0 인터페이스에 아이피만 할당해주면, 네임스페이스들의 네트워크에 도달할 수 있다.
ip addr add 192.168.15.5/24 dev v-net-0
ip netns exec blue ip route add 192.168.1.0/24 via 192.168.15.5
이제 ping 명령어가 먹힌다.
그런데, 아직 우리가 만들어준 v-net-0은 외부 세계와 단절되어 있다. 바깥 세상으로 통하는 유일한 문은 eth0이다. 그럼 어떻게 v-net-0을 eth0으로 연결해줄 수 있을까? 바깥 세상으로 나가는 게이트웨이를 추가해야 한다.
호스트는 아이피가 두개다. 192.168.15.5와 192.168.1.2다.
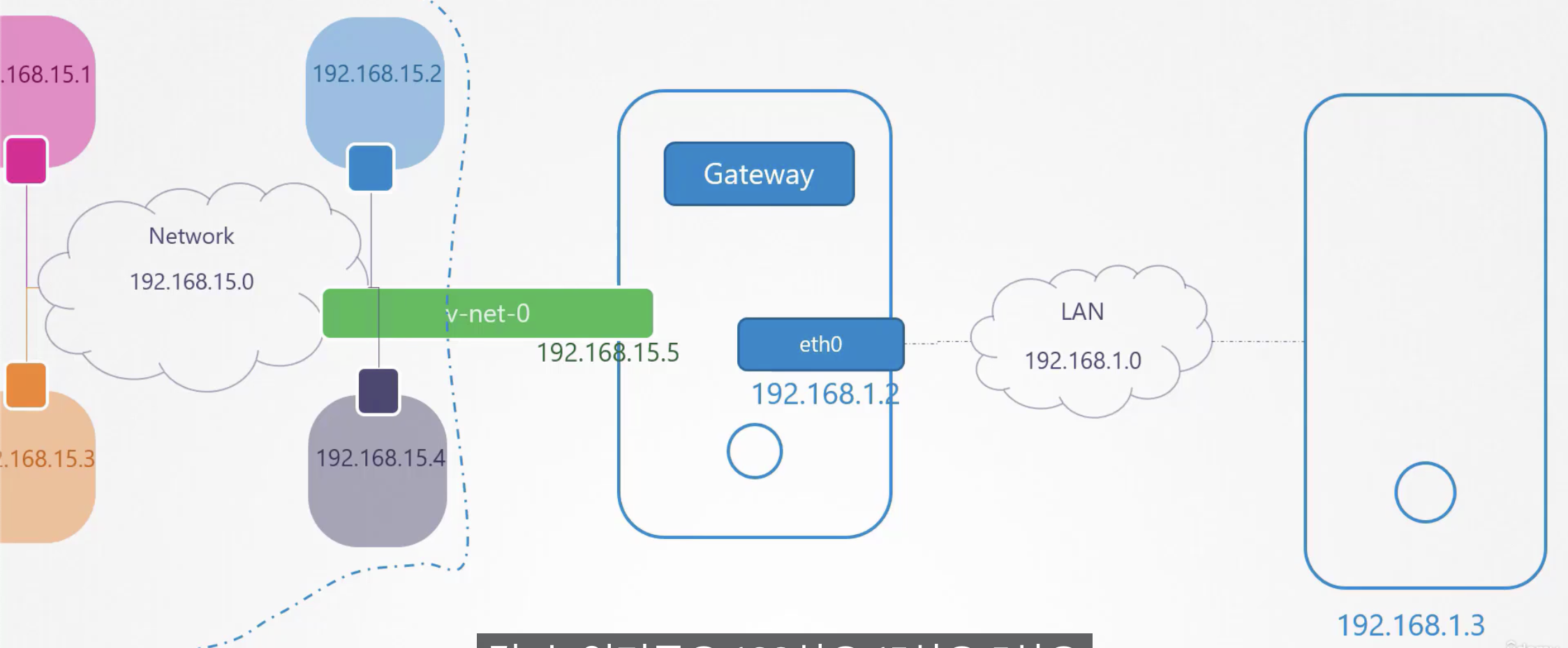 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이제 blue 네임스페이스에서 외부인 192.168.1.3으로 핑을 날리면 Not Reachable은 뜨지 않지만 여전히 응답 받을 수 없다는 것을 확인할 수 있는데, 이는 외부에서 내부로 들어오지 못하기 때문이다. NAT가 필요하다.
Prerequisite - Docker Networking
도커 네트워킹 옵션에는 몇 가지가 있다.
- None: 세상과의 완전한 단절
- Host: 호스트의 네트워크와 동일시
- Bridge: 사설 네트워크가 생성됨. 컨테이너들은 내부에 사설 아이피 주소를 가지게됨.
Docker는 docker0라고 하는 디폴트 브릿지 네트워크를 생성한다. 호스트에서 ip link 명령어를 통해 확인할 수 있다. docker0 인터페이스는 172.17.0.1/24를 할당받는다.
ip netns # 명령어로 네임스페이스 정보를 확인할 수 있음
컨테이너란 도커에 의해 생성된 네트워크 네임스페이스와 같다. 도커는 어떻게 컨테이너를 브릿지에 연결할까? 아까 이야기했듯 케이블이 생성된다.
ip link
# 도커 호스트에서 명령어를 실행하면
# docker0와 연결된 케이블을 확인할 수 있다.
ip addr
# 컨테이너 네임스페이스 안에서 실행하면 할당받은 아이피를 확인할 수 있다.
# 새 컨테이너가 만들어질 때마다 같은 과정을 거치게 된다.
도커는 어떻게 트래픽을 이동시키는가? 한 포트에서 다른 포트로 트래픽을 이동시키는 것? → NAT로 했다. iptables에 룰을 만드는 것
iptables \
-t nat \
-A PREROUTING \
-j DNAT \
--dport 8080 \
--to-destination 80
# Docker
iptables \
-t nat \
-A DOCKER \
-j DNAT \
--dport 8080 \
--to-destination 172.17.0.3:80
실제로 호스트에서 iptables -nvL -t nat 명령어를 통해 확인해보면 DNAT이 생성되는 것을 확인할 수 있다.
Prerequisite - CNI
 이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
이미지 출처: Certified Kubernetes Administrator (CKA) with Practice Tests(Udemy)
모든 컨테이너 런타임들이 이러한 비슷한 작업을 거치는데, 이러한 작업을 묶어서 “브릿지”라는 프로그램을 만들었다. 이제 컨테이너 런타임들은 이런 작업을 반복해서 수행할 필요 없이, 브릿지를 호출하여 네트워크 구성 작업을 진행할 수 있다.
bridge add <cid> <namespace>
만약 컨테이너 런타임들이 새로운 네트워크 유형을 만들고 싶다면 어떻게 해야할까? 어떤 args와 cmd를 제공해야 할까? 컨테이너 런타임에 네트워크 유형이 맞게 동작시키려면 어떻게 해야할까? 어떻게 동작을 보장할 수 있을까? 여기서 표준이 필요하다. 방금 이야기한 bridge도 CNI 플러그인이다. CNI는 플러그인이 어떻게 구성되어야 하는지를 정의한다.
상용화된 여러 CNI 플러그인들: BRIDGE, VLAN, IPVLAN, MACVLAN, DHCP, host-local 등